
Hydra Network Walkthrough
This page explains the design, architecture and the implementation of hydrus server along with a few use cases for the same. Also the interactions and internals of a smart client (Hydra agent) connecting to the server are considered. See Home for a general intro.
REST to Hydra to hydrus
To understand how hydrus represents REST resources and how the developer is helped to work with Hydra, it is possible to start from thinking at Hydra as generic framework that describes REST API resources to make data exchanges automated.
An instance and its classes
Instances belonging to a Resource are named Items in hydrus. It is possible to perform CRUD operations (via HTTP) over Items. At a slightly more abstract layer, the REST Resource is of a kind of an hydra:Resource, all the instances of the same resource are members of a hydra:Collection. As Hydra inherits from RDF, thanks to the framework it is possible to represent the API as a graph.
the ecosystem: servers and smart clients
hydrus allows the developer to take advantage of this powerful description by abstracting away the complexity of RDF and to work on the REST interface layer.
Hydra agent interacts with one or more hydrus instances to represent and navigate resources for the sake of data consumption. The client-side tools in the ecosystem are basically any client that complies with Hydra’s specs, starting from the official Typescript implementation Heracles.ts but also hydra-python-agent.
The tools in the ecosystem works on top of a distributed architecture that is described below from its foundationals classes in the ORM to the interface layer.
Table of contents
- RDF and Hydra
- hydrus-based cloud system
- hydrus full stack
- Multi-layered Database Design
- Data flow
- Use cases
RDF
For a short overview of RDF and Hydra see Home.
Example: hydrus as a cloud system
hydrus servers are highly decoupled web servers that allows installation of multiple services in parallel. This is possible by-design as every hydrus instance is automatically querable by Hydra smart client (e.g. Hydra agent). A hydrus system can be composed of single server or a multiplicity. Whatever is the system’s layout, a superuser/developer that carries on the activities of engineering and developing the system can manage access privileges to the APIs in the system. External smart clients can query the APIs in the system, according to the privileges defined by the superuser. Here a simple diagram of a cloud deployment with three hydrus “module-servers” and three external smart clients:
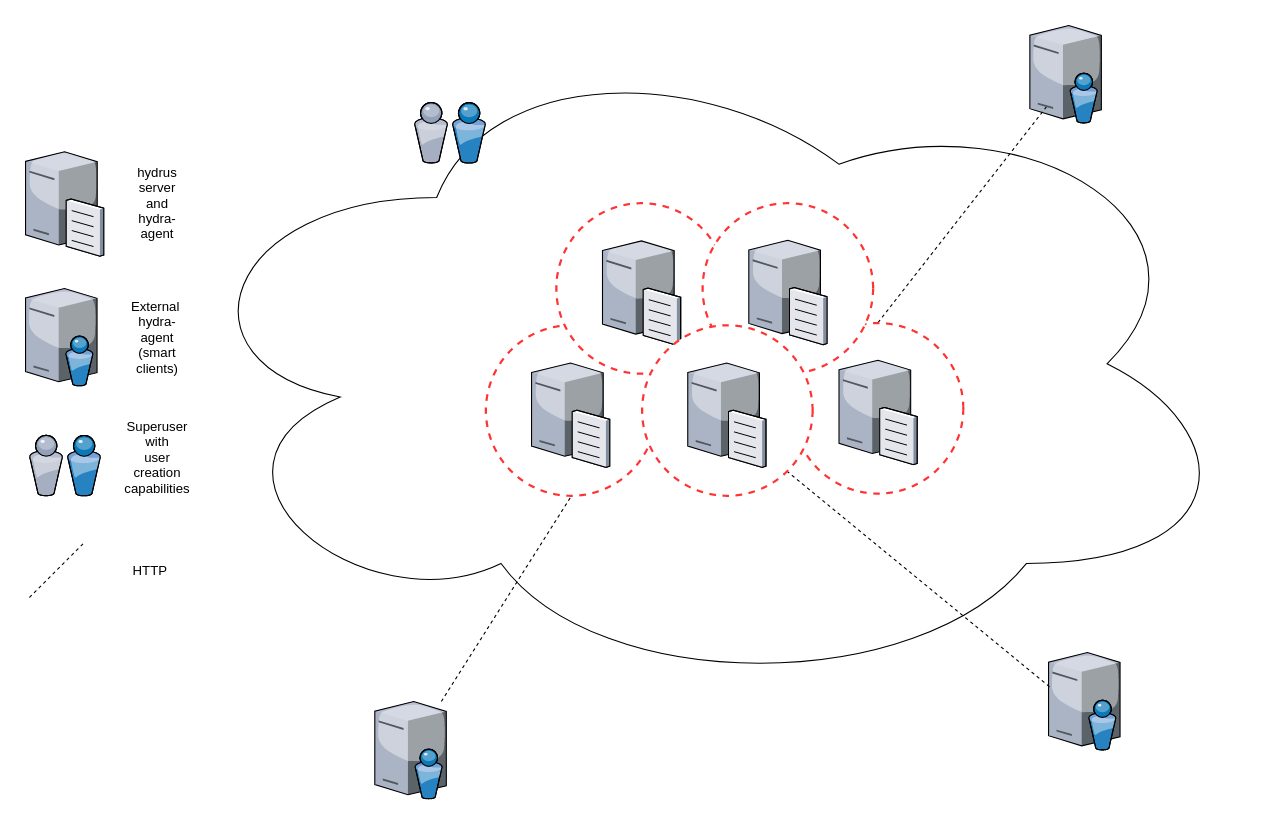
Hydra-based data networks
The different hydrus “modules” that build up an hydrus cloud deployment are designed to be highly decoupled Hydra-aware APIs. Design of the APIs follows the Hydra draft so that smart clients querying capabilities can be deployed on the hydrus-powered services. Here an example of a Hydra network in a simple diagram:
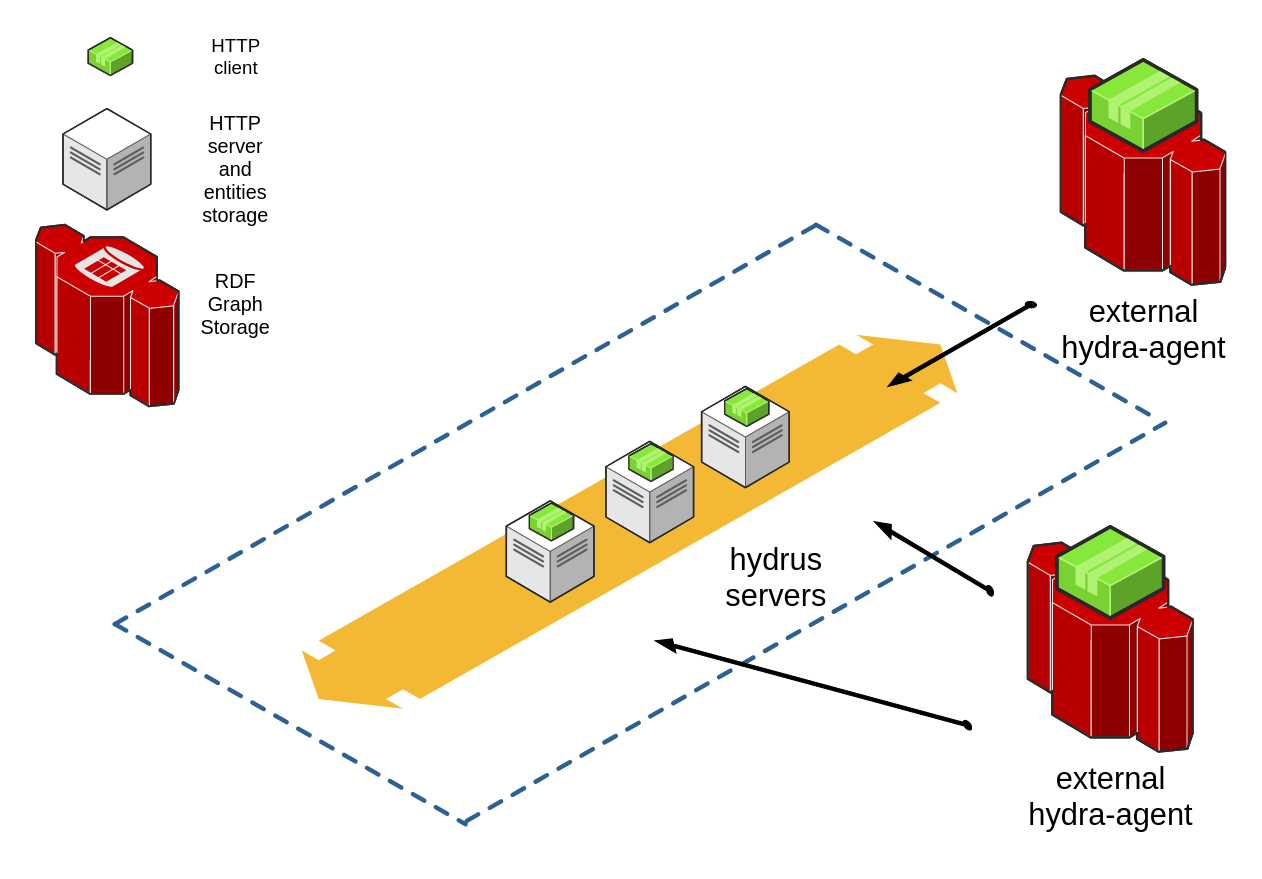
The different hydrus instances-servers are designed in the same cloud, any Hydra-aware client with the right privileges can access the ApiDoc and the data in the servers, so to build its own representation of the data cloud. hydrus instances may or may not have attached a client as well, to provide routing or connectivity to data stored in another instance.
Data storage
Server-client data segregation
Data storage capabilities are provided both in the server (hydrus) and in the smart client (Hydra agent) for different puproses:
- hydrus and its database (the grey box in figure 2) hold what we can call, in common use, the “data” itsef (as opposed to the abstract layer that instead describes how data types/classes are interconnected, commonly the “metadata”): data are simply instances of the resources/classes the system is serving. The
ApiDocis a JSON-LD string published by the server (via a proper HTTP header as per Hydra spec) that describes classes of resources and their relationships (as above, “metadata”). hydrus’s database is a relational database with tables for every resource/class, the schema of the database is generated by the parsing of theApiDoc. - Hydra agent (the green box in figure 2) and its datastore (the red component in figure 2) hold the (meta)data necessary for the client to know where to access and fetch the data. Initially, the datastore is a graph-store in which the resources classes and their relationships are stored as a graph. As the smart client discovers the servers in the network, the graph is enriched by the resources found in other
ApiDoc(metadata is stored by parsing documentation strings, properties of data instances are stored by fetching resources via CRUD operations). When the smart client starts fetching instances it can add to the graph the relationships between instances as described by their metadata and data, acting as a store for triplets of nodes (as per RDF triples, a node subject with an predicate and an object).
Annotations: the complete data of every instance reached by the client is still only in the server, the client holds its own representation of the state of the data. This creates great challenges in terms of data integrity and representations’ synchronization. For an overview of the challenge of distributed data networks see here. The Hydra ecosystem does not aim to develop a solution for distributed storage but to implement the W3C Hydra Draft, focusing on defining tools for servers-clients or also clients-clients interactions via HTTP leveraging the REST paradigm; with this scope, a synchronisation mechanism is under development with issue #300.
A multi-layered data abstraction
The design of both database and datastore takes into account some of the different layers of representations possible using RDF. This multi-layered data layout tries to give tools to fashion representations using metadata and data concepts as useful abstractions.
Typically, statements (triples) are stored in the Graph according to 4 different types of layers. These layers make up the Knowledge Base that the REST layer queries.
NOTE: for the sake of this text, the following tuple of words are synonyms:
- statement is triple
- predicate is property
Entities and properties are assigned to different layers according to their level of abstraction. The most abstract level considered is the one most related to generic most popular RDF ontologies/vocabularies. Getting closer to the REST interface, the levels become less abstract until it is possible to represent relationships between instances or proper objects. This layout is closed, as in any definite Tree-like representation, by terminals or values that store the quantitative values themselves (strings, numbers, any data types). We call properties that relate “classes” to “classes” (like the ones at the most abstract level) as AbstractProperty and the others (relating less abstract kind of entities) as InstanceProperty.
Abstract Layer
Class » Property » Class [GraphCAC]
A statement that links two abstract classes is a “CAC” statement. This is the most abstract level of relationship stored. Two classes are related by a AbstractProperty that describes how they relate.
For example:
- the class of
Fishes relates with the propertyliveHabitatto the classWateryHabitat. - Furthermore, if we walk up the the hierarchy in which this relation may be included, the
WateryHabitatcould be in a relation ofrdf:SubclassOfwithHabitatas a generic class for all the habitats. - Furthermore,
HighPressureSubMarineHabitatcould be ardf:subClassofMarineHabitatthat is itself a subclass ofWateryHabitat, and so on. The one above are all considered asAbstractPropertyfor the sake of storing them in hydrus’ datastore.
This is a generic overview of how RDF works to relate classes of objects. This logic works also with instances of objects (the fish named Joy is of kind Acanthurus coeruleus); also families and kinds of objects can be represented as classes. Very generic kind of classes (like classes of relations) are described in vocabularies called “upper-ontologies”.
Paragraphs below describe less abstract statements.
Infralayer between resources and classes
Resource » Property » Class [GraphIAC]
A statement that links a Resource to an abstract class is a “IAC” statement. A Resource can be also seen as an instance representing a collection of instances (not a class in the abstract, but a more concrete set/group of objects). In the REST layer a Resource is addrressed as Items. This kind of entity relates to an abstract class as the ones described in the “CAC” group. This class of statements are stored in the “Graph IAC”.
For example:
- the Resource that is the collection of
Fishand the Resource that is the collection ofMolluscahave both a propertyliveHabitatthat points toWateryHabitat
Resources layer
Resource » Property » Resource [GraphIII]
A statement that relates two instances or collections of items is a “III” statement. In this layer and in the ones described below, properties are meant to be of kind InstanceProperty.
For example:
- an instance of Resource/Class
Fishcan have a propertysameHabitatpointing to an instance of Resource/ClassMolluscabecause they both lives in the Sargasso Sea. In other words, the fish Joy has the same habitat as the mollusca Rachel. The Knowledge Base express its power as in the same datastore Joy may also be part of multiple statements, like: Joy is of a kind Teleost (an infraclass/family of fishes according to marine biologists).
Values layer
Resource » Property » Value [GraphIIT]
A statement that relates an instance to a constant is an “IIT” statement. A Value can be a string or a number or any other kind of RDF-supported data types. Usually a value is also a Terminal in the sense that it is an entity that state itself and is not related furthermore to an object. Some values are not terminals as may contain a unit of measurement (“2.3 kilos”), in that case the unit of measurement can be itself semantically linked to an entity outside of the instance (“kilos” can be semantically linked to the vocabulary describing Weights and Measures).
hydrus diagram
Below is the schema diagram for hydrus database design, instances are stored in tables representing their hierarchical representation:

graph-store diagram
(WIP: add diagram for data representation used in python-hydra-agent)
…
Data Flow
Here is a small illustration as to how data flows in hydrus.
Hydra API Documentation to server endpoints:

RDF/OWL declarations to server endpoints:

Use cases
This section explains hydrus’s design and a use case for the same. For the demonstration, the server has the Subsystems and Spacecraft vocabularies.
Here is an example of a system used to serve data using the components of hydrus:

A simple example explaining the use of the above architecture would be:
- User types in the query “What is the cost of a Thermal Subsystem?”.
- Middleware uses NLP to extract keywords “Thermal Subsystem” and “cost” and maps it to the Hydra instances and properties present at the server.
- Middleware passes these instances and the underlying query to the client.
- Client models a request and uses the API endpoints to extract the given information from the server.
- Server replies with the required value.
- Client serves data to the User.